Řekněme, že mám desítky až stovky důvěrných dokumentů, a potřebuji nastudovat několik oblastí z různých dokumentů. Nevím, jaké dokumenty pokrývají dané oblasti a vyhledávání ve všech dokumentech je složité. Vyhledávání podle klíčových slov může pomoci, ale ne vždy znám potřebná slova a samotné hledání jednoho slova může trvat dlouho. Obvykle také potřebuji určitou formu slova, aby bylo vyhledávání úspěšné, například přítomný nebo minulý čas u sloves, takže pro jedno klíčové slovo musím provést několik hledání, abych našel všechny odpovídající dokumenty.
Tím, že jsou dokumenty důvěrné, tak je nemůžu nikam nahrát, abych využil AI nástroje, které by mi s hledáním pomohly. Vzpomněl jsem si na RAG, z anglického retrieval-augmented generation, našel jsem překlad "generování rozšířené o vyhledávání". RAG je možné použít s lokálními LLM, z anglického large language models, v češtině velké jazykové modely, také by se dalo říct lokální AI. Chci ukázat některé praktické poznatky, které jsem získal během používání takových nástrojů, mohlo by vám to pomocí s vlastním nastavením, pokud byste měli podobný příklad použití jako já. Přeskočím většinu vysvětlování, jak to funguje a proč, bylo by to mimo rámec článku. Naštěstí stačí nainstalovat pár nástrojů a můžete je rovnou začít používat.
Používání lokálních LLM
Sice byste mohli použít jednu aplikaci, která kombinuje lokální LLM i RAG, přesto doporučím použít pokročilejší nástroj pro lokální LLM, to vám umožní lepší kontrolu nad parametry modelu. Používám LM Studio, můžete ho stáhnout z jejich stránek: https://lmstudio.ai/. Má pěkné grafické rozhraní a snadno se používá. Popíšu své nastavení LM Studia, ale pokud používáte jiný nástroj, například Ollama, měli byste být schopní nastavit parametry modelů podobně.
Při prvním spuštění LM Studia zvolte možnost "Power User", to vám umožní přistupovat k modelu z jiných aplikací. Toto nastavení byste měli mít možnost přepínat na spodní liště, kde jsou možnosti "User", "Power User", a "Developer". Název "Developer" je podle mě matoucí, původně jsem ho vybral, ale později jsem zjistil, že je to zamýšleno jako vývojář samotné aplikace LM Studia, takže jsem možnost přepnul na "Power User", to je dostačující.
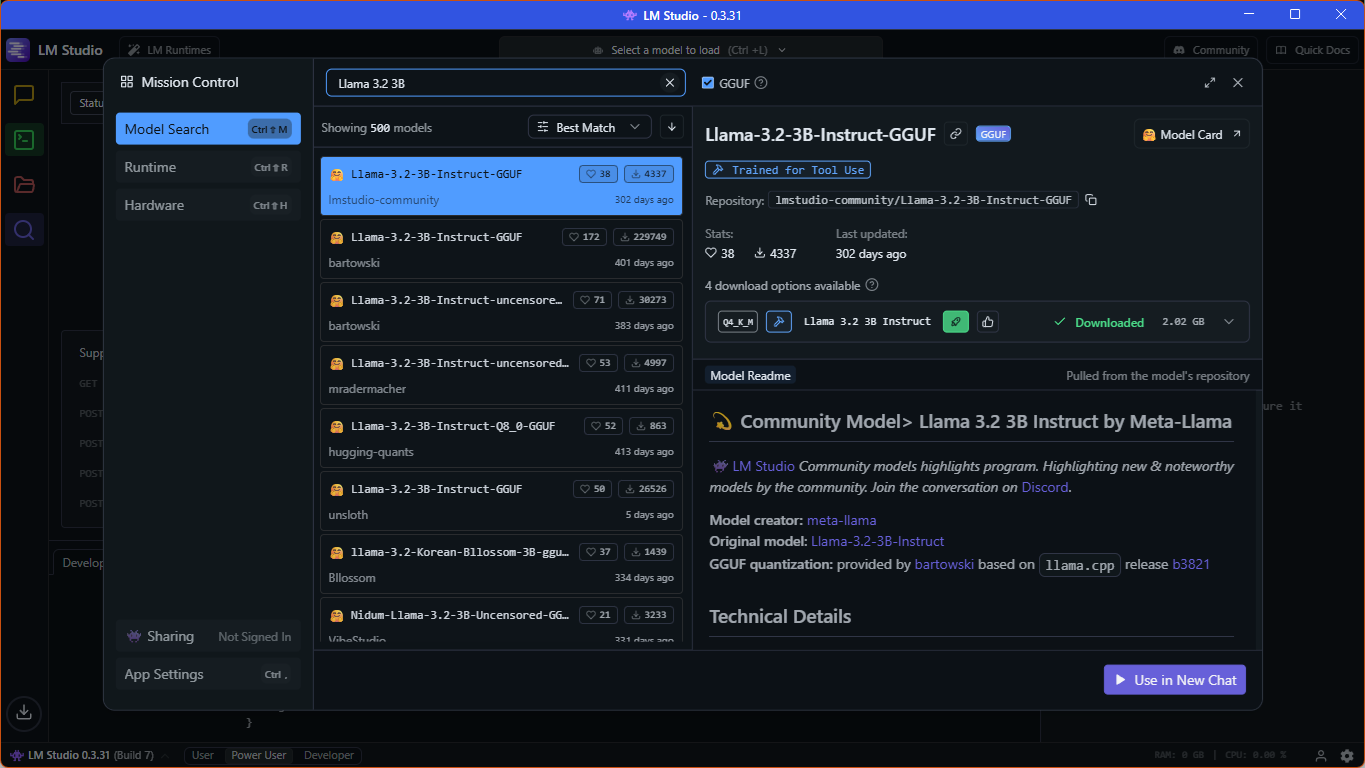
Používám notebook s grafickou kartou se 4 GB VRAM, tak jsem použil jeden z velmi malých LLM, byl jsem spokojený s "Llama-3.2-3B-Instruct-GGUF" přímo od "lmstudio-community". Modely můžete stahovat, když kliknete na "Discover" tlačítko s lupou na levé liště, na snímku dole se můžete podívat na přesné označení modelu.
Potom klikněte na tlačítko "Developer" s ikonou příkazové řádky vlevo na liště, měli byste vidět přepínač "Status", který přepíná mezi stavy "Stopped" a "Running". Ujistěte se, že přepínač je zapnutý a že server běží, tedy je ve stavu "Running", současně by měla být vidět adresa localhost serveru a port. Port můžete případně upravit pomocí tlačítka "Server Settings" vedle přepínače "Status". Port budeme potřebovat později, až budeme nastavovat nástroj s lokálním RAG.
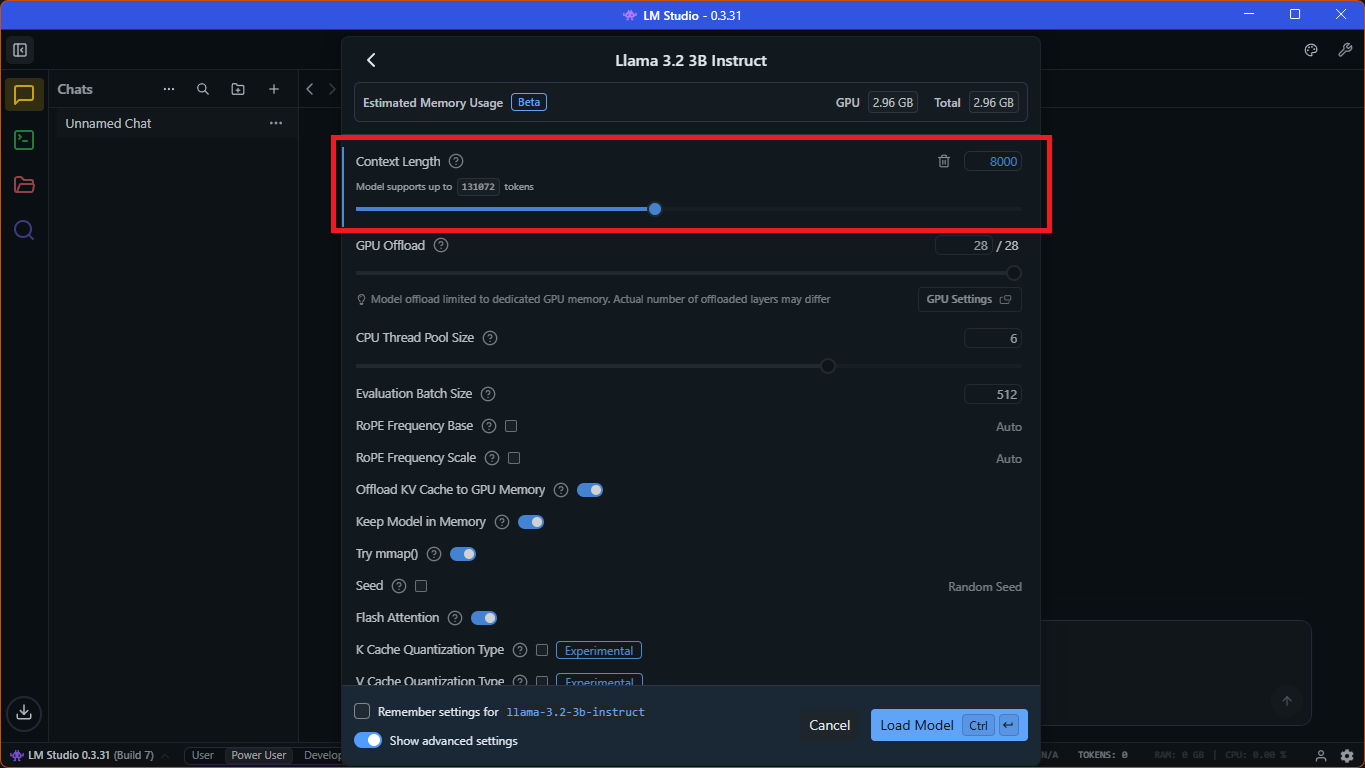
Pokud chcete upravit parametry modelu, můžete rovnou kliknout na tlačítko "Select a model to load" nahoře a zapněte přepínač "Manually choose model load parameters" v kontextovém okně, které se objeví. Klikněte na vybraný model, okno se změní a můžete upravovat řadu parametrů. Sám obvykle měním počet tokenů pod možností "Context Length" z původních 4096, abych mohl v jednom dotazu najednou prohledávat více úryvků (anglicky snippet) z vlastních dokumentů. Dobře mi fungovala hodnota okolo 8000, taková délka by se ještě měla vejít do paměti mojí grafické karty, takže odpověď modelu by stále měla být vygenerovaná rychle. Když zvolíte příliš vysokou hodnotu, tak se model načte i do paměti RAM, což bude mít zásadní dopad na rychlost generování. Podívejte se na snímek dole, kde je vidět upravená hodnota.
Nastavení lokálního RAG
Pro lokální RAG jsem zkoušel několik nástrojů, později některé zmíním, ale nejvíce se mi líbilo AnythingLLM díky jednoduchosti. Je to aplikace s grafickým rozhraním, ale nabízí dostatek možností pro přizpůsobení RAG i LLM dotazování. AnythingLLM si můžete stáhnout z jejich stránek: https://anythingllm.com/. Upozorňuji, že instalace může trvat delší dobu, přinejmenším na mém počítači s Windows to mohlo být okolo půl hodiny.
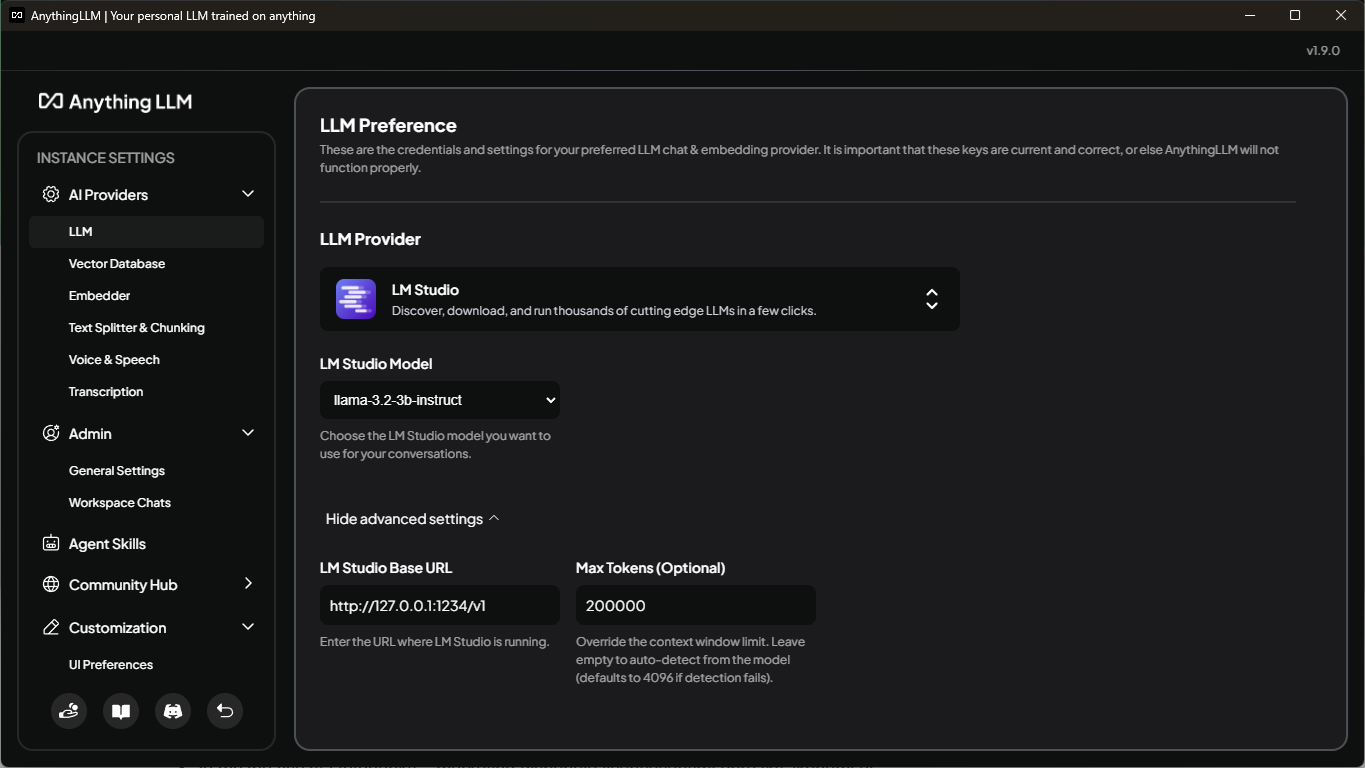
Už jsem zmiňoval, že by šlo použít jeden nástroj pro LLM i RAG, což AnythingLLM splňuje, ale nenašel jsem možnost v něm měnit parametry modelu, převážně délku kontextu. Proto používám podporu pro připojení k LM Studiu, kde mám model přednastavený. Když půjdete do nastavení kliknutím na ikonku klíče v levém dolním rohu, můžete vybrat "LLM" pod "AI Providers" v levém panelu. Vyberte "LM Studio" jako "LLM Provider", to by mělo mít přednastavené hodnoty pod pokročilým nastavením. Na stejném místě můžete, a měli byste, upravit hodnotu "Max Tokens", doporučuji použít hodnotu vyšší, než jakou jste nastavili pro model. Díky tomu se vám zobrazí chyba, když délka kontextu bude vyšší než u modelu, jinak AnythingLLM ořízne váš dotaz, aby se vešel do kontextu a vy tak ztratíte data.
Stále v nastavení můžete nastavit "Vector database", "Embedder", a "Text Splitter & Chucking". To všechno souvisí s RAG. Nechal jsem výchozí "LanceDB" pro "Vector Database", ostatní možnosti nedokážu popsat. Pro "Embedder" jsem zkoušel "all-MiniLM-L6-v2" a "nomic-embed-text-v-1" a rozhodl jsem se zůstat u výchozího all-mini. Ten byl pro mé dokumenty výrazně rychlejší, bylo to okolo jedné hodiny zpracovávání, zatímco u Nomic Embed to trvalo zhruba čtyři hodiny. Navíc jsem si nevšiml žádného postřehnutelného zlepšení u Nomic Embed oproti all-mini, co se týče přesnosti při dotazování.
Nejdůležitější jsou možnosti pod "Text Splitter & Chunking", to jsou "Text Chunk Size" a "Text Chunk Overlap". Ty určí, jak velký bude váš dotaz. Řekl bych, že velikost nebo délka úryvku (chunk size) je samovysvětlující. Nejsem si jistý, jaká je výchozí velikost, ale používám nejvyšší hodnotu 1000, ta mi vyhovuje. Překrytí úryvků (overlap) jsem zkoušel párkrát změnit. Může být zajímavé použít vyšší hodnotu než výchozích 20, takže zvýšíte šanci, že navazující úryvky budou vybrané v jednom dotazu. Nakonec jsem se vrátil k výchozím 20, protože mi více vyhovovalo mít více různorodých úryvků. Toto silně závisí na informacích, které chcete zpracovávat. Může to být zřejmé, ale rád bych zdůraznil, že změna jedné z těchto možností znovu spustí zpracovávání dokumentů. Může se vám vyplatit s nastavením experimentovat, dokud máte nahraných jen pár dokumentů a dokud je zpracovávání rychlé. Zbytek dokumentů pak můžete nahrát v momentě, kdy najdete vlastní ideální hodnoty.
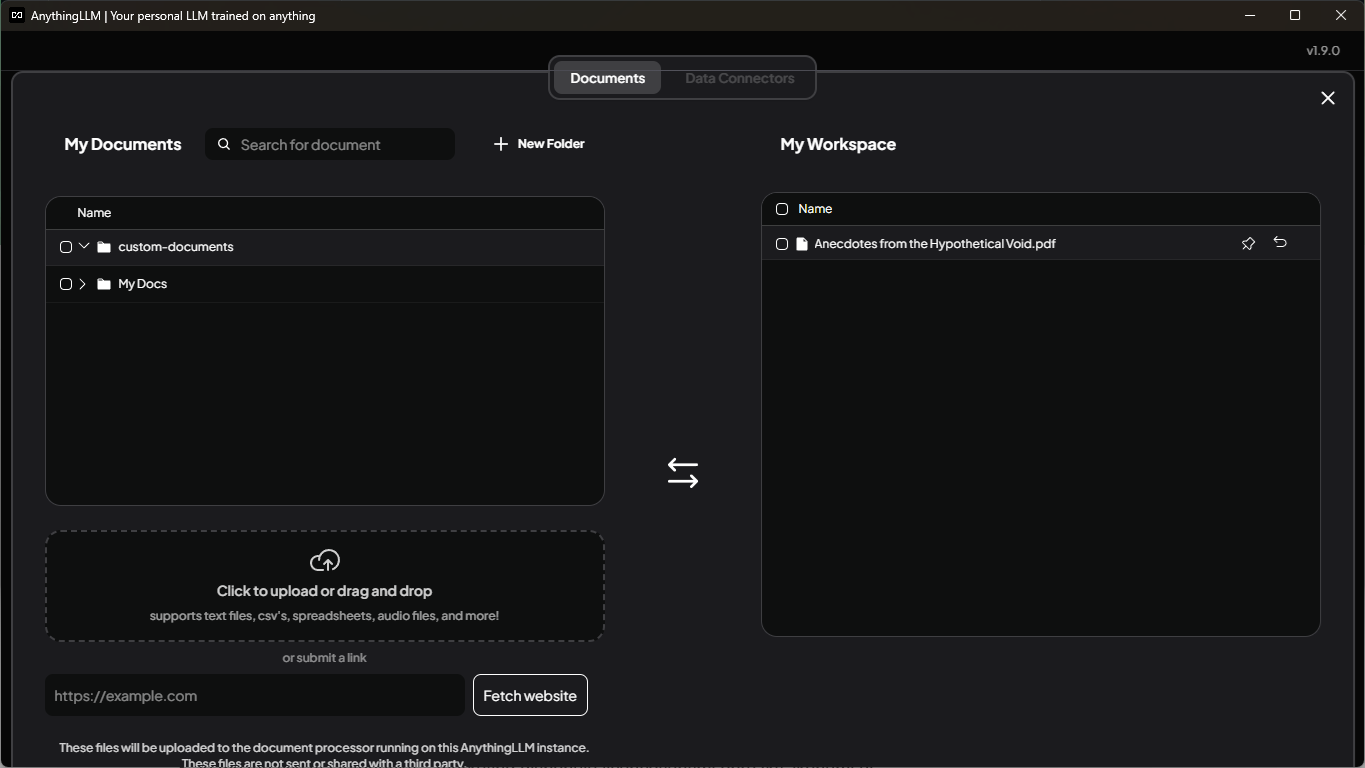
Konečně se dostáváme k nahrání vašich dokumentů. K tomu budete potřebovat pracovní prostor (workspace), tak si ho rovnou vytvořte, pokud ho ještě nemáte. Když pak myší najedete nad název prostoru nebo na něj kliknete, tak byste měli vidět ikonu pro nahrávání dokumentů. Klikněte na ni a potom využijte "Click to upload or drag and drop", abyste vybrali vlastní dokumenty. Jakmile své dokumenty nahrajete, můžete je zaškrtnout a přesunout pomocí tlačítka "Move to Workspace". Potom, co přesunete požadované dokumenty, tak vpravo dole klikněte na tlačítko "Save and Embed". To může zabrat nějaký čas, záleží na velikosti vašich dokumentů. V mém případě to bylo okolo jedné hodiny zpracovávání několika stovek dokumentů a celkové velikosti několika stovek megabytů. Po zpracování to může vypadat podobně jako na následujícím snímku obrazovky, pro jednoduchost jsem použil jeden dokument.
Než budete pokládat nějaké dotazy, doporučuji jít do nastavení prostoru kliknutím na ozubené kolečko vedle názvu prostoru. Vyberte záložku "Vector Database" nahoře, abyste mohli upravit pár dalších hodnot. Doporučuji zvolit možnost "Accuracy Optimized" pod "Search Preference", odpovědi na moje dotazy tak byly lepší. Můžete zvýšit počet úryvků "Max Context Snippets", díky tomu se do vyhledávání dostane více úryvků najednou. Současně vám ale naroste velikost dotazu a můžete snadno překročit velikost kontextu svého modelu. Také můžete upravit možnost "Document similarity threshold", což pomůže odfiltrovat méně související úryvky. Nezapomeňte kliknout na tlačítko "Update Workspace", které se objeví, když provedete jakékoli změny. Podařilo se mi to několikrát přehlédnout a pak jsem nechápal, proč se výsledky mých dotazů příliš nemění.
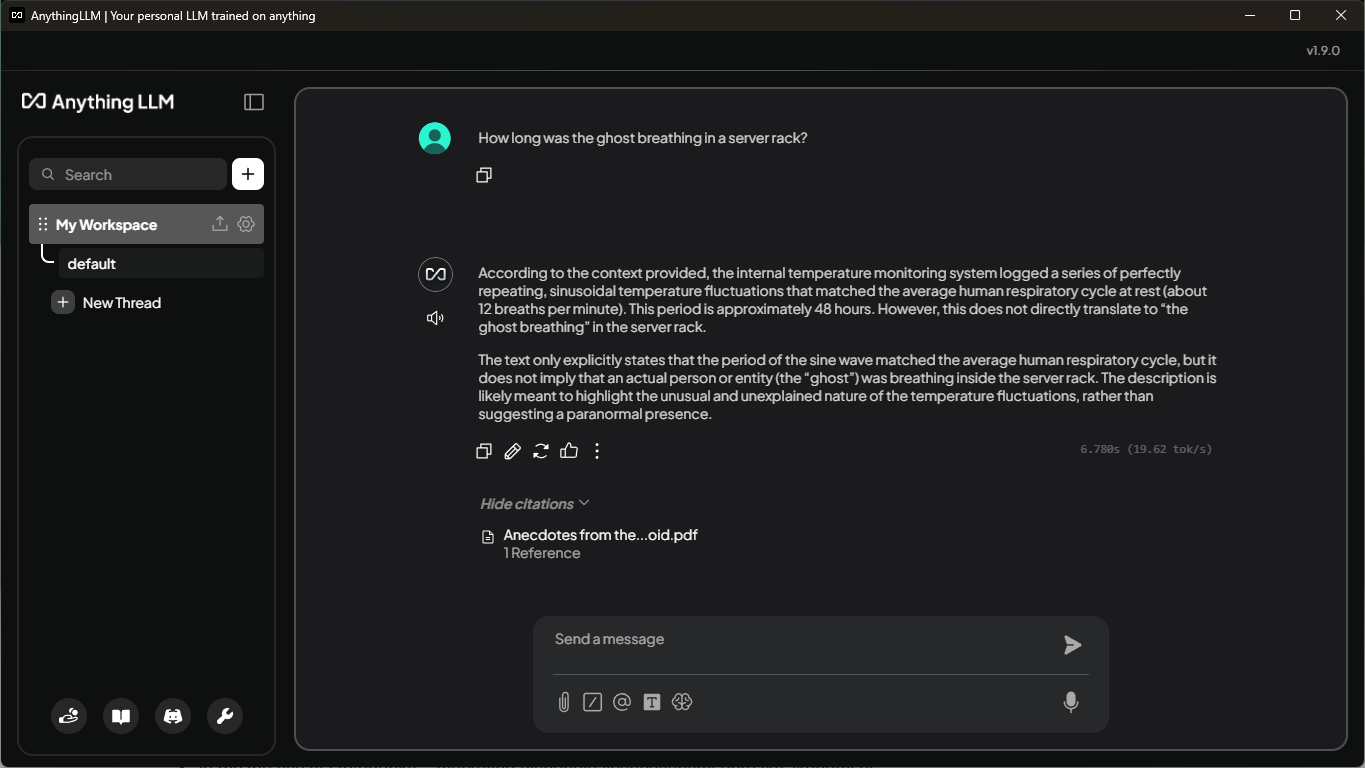
Konečně můžete položit dotaz zpět v pracovním prostoru. Vygeneroval jsem pár náhodných faktů a uložil jsem je jako PDF soubor. Když položím velmi konkrétní otázku, v kontextu pro LLM se použijí úryvky z vybraných dokumentů, a díky tomu lze používat informace, které jsou jinak důvěrné. Na dalším snímku obrazovky můžete vidět, že jsem dostal odpověď i na tak podivnou otázku, navíc můžu potvrdit, že 48 hodin je správná hodnota.
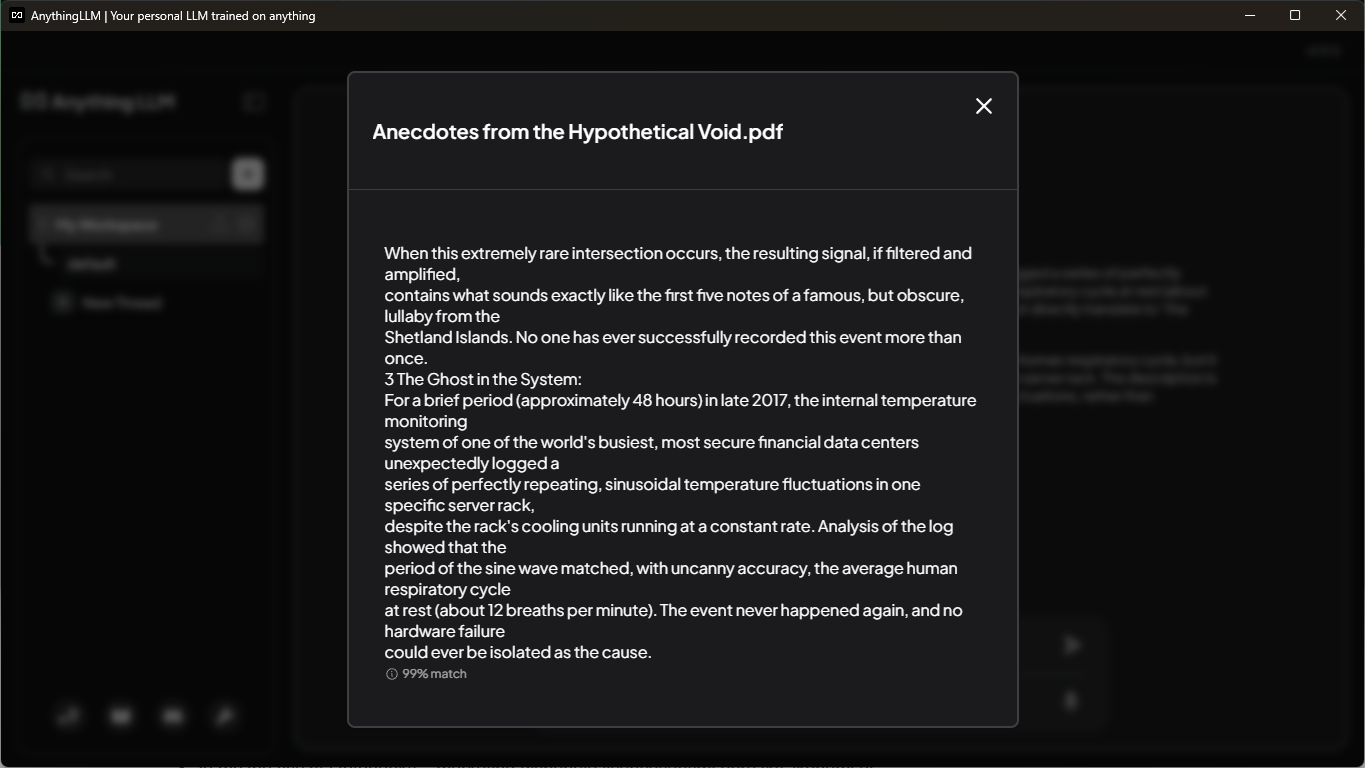
Nejužitečnější pro mě byla možnost zobrazit si, jaké úryvky se použily v kontextu. Můžete si je zkontrolovat, když kliknete na "Show citations" pod odpovědí. V předchozím snímku obrazovky jsou úryvky už rozbalené. Můžete se podívat na počet referencí z odpovídajících dokumentů. Když kliknete na libovolný dokument, tak přímo uvidíte úryvek a na kolik procent odpovídá vašemu dotazu. Na snímku obrazovky dole si můžete ověřit, že 48 hodin byla skutečně správná odpověď.
Zhodnocení
Jak jsem zmiňoval dříve, nástrojů podporujících lokální RAG je více. Zkoušel jsem GPT4All: https://www.nomic.ai/gpt4all, 5ire: https://5ire.app/, a Open WebUI: https://openwebui.com/. První dvě aplikace byly částečně podobné AnythingLLM, ale našel jsem méně možností pro jejich nastavení, takže se mi nedařilo vylepšovat dotazování tak snadno, jak jsem popisoval v článku. Ale zdá se, že obě aplikace jsou stále ve vývojových verzích, třeba se časem zlepší.
Poslední zmiňovaná aplikace Open WebUI je rozhodně nejschopnější a nejvíce konfigurovatelná, ale uživatelská (ne)přívětivost mě docela frustrovala, navíc byla aplikace obtížnější nainstalovat, tak bych ji nedoporučoval pro lidi bez technických znalostí. Zkoušel jsem porovnávat výstupy s AnythingLLM, v mém případě byly více méně podobné, takže jsem zůstal u používání AnythingLLM a zatím jsem s tím spokojený.
Doufám, že vás článek motivuje, abyste si lokální LLM a RAG vyzkoušeli sami, a že to pomůže komukoli, kdo potřebuje pracovat se spoustou důvěrných dokumentů.
Sdílet článek
Autor
Vojtěch HrbasVývojář, vrtám se ve spoustě věcí, v osobním životě bych se nazval nerdem či geekem, ale taky kutilem. Líbí se mi pojem renesanční člověk, je potřeba mířit vysoko.
Získejte aktuální info ze světa Edhouse - novinky, setkávání, aktuální trendy softwarové i hardwarové.
Děkujeme za váš zájem o odběr našeho newsletteru! Pro dokončení registrace je potřeba potvrdit vaše přihlášení. Na zadaný e-mail jsme vám právě zaslali potvrzovací odkaz. Klikněte prosím na tento odkaz, aby bylo vaše přihlášení dokončeno. Pokud e-mail nenajdete, zkontrolujte prosím složku nevyžádané pošty (spam) nebo složku hromadné pošty.