“Ach jo, další generický blábol o tom, jak velké jazykové modely změní svět k nepoznání…” Přesně to vás dost možná napadlo, když jste viděli nadpis. Akorát že vůbec! Tento příspěvek neslibuje sci-fi revoluci, jeho obsah je mnohem prozaičtější. V Edhouse jsme jen potřebovali vyřešit jeden zdlouhavý, ubíjející úkol – nasbírat data o stovkách firem před blížícím se veletrhem. Měli jsme na výběr: buď obětovat duševní zdraví nebo strávit čas vývojem něčeho, co to udělá za nás. Vybrali jsme si to druhé a postavili vlastního agenta. Jmenuje se Golden Retriever, žere tokeny místo granulí a na rozdíl od nás ho baví číst naskenované účetní závěrky.
Na začátku nebyl žádný velkolepý plán na stavbu autonomního agenta. Byla jen tabulka se 700 řádky a nechuť trávit týdny manuálním copy-paste maratonem. Poměrně rychle jsme zavrhli klasickou cestu v podobě univerzálního skriptu, protože napsat scraper se sadou regulárních výrazů, které by spolehlivě vytáhly informace ze stovek webových stránek, by byla programátorská sebevražda. Moc jiných možností automatizace neexistovalo, a tak padla otázka: “A co kdybychom na to pustili tu kouzelnou ‘áí’ ?”
Snowball efekt: Když zjistíte, že to fakt funguje
Následovala rychlá rešerše frameworků, AI-native nástrojů a knihoven (nepopírám použití ChatGPT), které by pro náš use-case mohly dávat smysl, trocha inspirace z YouTube a pak už VS Code, pár řádků v Pythonu, zkusit provolat API OpenAI, sestavit agenta v LangChain frameworku, dát mu první nástroj. Výsledek?
"Popravdě, ono to negeneruje o nic horší výstupy než manuální analýza.”
Najednou to dávalo smysl. Pokud modelu předhodíme chaos z webu, on si v něm ten kontext najde sám. Nepotřebujeme psát parser pro každou stránku zvlášť. Věděli jsme, že zase narazíme na jiné komplikace, že bude problém s halucinací, konzistencí výstupů a že jeden slibně vypadající pokus nic neznamená. Ale od té chvíle bylo jasno, že AI dáme šanci.
Postupně pak přibývaly nástroje a celé se to nabalovalo jako sněhová koule.
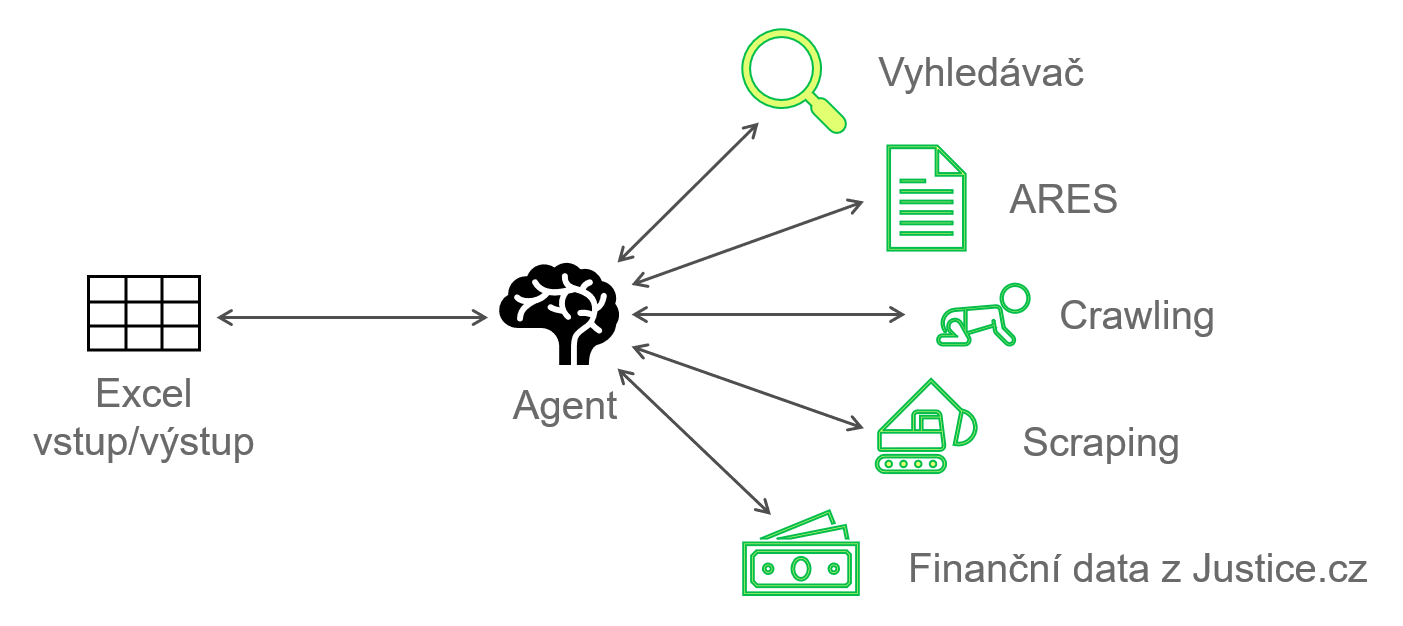
LangChain: Framework pro orchestraci a vývoj aplikací nad LLM. Řídí logiku, paměť a posloupnost kroků celé pipeline.
Tavily: Vyhledávač optimalizovaný pro AI agenty. Místo seznamu odkazů plného reklam vrací strukturovaný kontext, který slouží k prvotní identifikaci firmy.
Firecrawl: Open-source nástroj pro crawling a scraping, který převádí webové stránky do čistého Markdownu. Provozujeme ho lokálně v Dockeru, abychom měli kontrolu nad tím, co a jak stahujeme.
Vlastní Python integrace: Vlastní moduly pro komunikaci s registry a veřejnými rejstříky.
GR schéma
Architektura: Kde končí autonomie a začíná determinismus
Jak jsme očekávali, téměř okamžitě jsme při vývoji narazili na zásadní problém LLM: halucinace a nekonzistentnost. Pokud jsme agentovi nechali příliš volnou ruku nad postupem a volbou nástrojů, často se zacyklil, zapomněl cíl, přeskakoval důležité kroky a vracel neúplné, a hlavně nekonzistentní výstupy. Kognitivní zátěž byla příliš vysoká a plně autonomní agent ve smyslu ReAct (Reasoning – Acting), kdy agent přemýšlí → koná → pozoruje → zase přemýšlí, tedy pro naše potřeby nedával smysl.
Museli jsme proto upustit od maximální autonomie a přejít k řízené pipeline. Python drží pevnou strukturu procesu, AI slouží jako kognitivní engine uvnitř jednotlivých kroků a mozek, který vyhodnocuje výstupy z jednotlivých nástrojů a rozhoduje, jestli je v pořádku pokračovat dalším krokem.
Výsledný proces vypadá takto:
GR pipeline
Vstup: Skript načte řádek ze vstupního Excelu (název firmy).
Identifikace: Agent dostane název a pomocí nástroje Tavily vyhledá digitální stopu firmy, tedy oficiální webové stránky a IČO.
Validace: Nalezené IČO se ověřuje proti veřejnému registru ARES. Pokud data nesedí nebo firma neexistuje, proces se zastaví či restartuje. Zde není prostor pro kreativitu modelu.
Discovery: Pokud je subjekt validní, nastupuje Firecrawl. Ten zmapuje strukturu webu (sitemap). Kvůli omezenému kontextovému oknu (context window) nestahujeme celý web, ale agent pomocí LLM vybere jen relevantní podstránky (např. O nás, Kariéra, Produkty, Reference).
Scraping: Vybrané stránky jsou staženy a převedeny do čistého Markdownu, zbaveného HTML balastu.
Extrakce a analýza: V tomto kroku nastupuje hlavní "inteligence". Modelu předložíme vyčištěný text z webu a striktní Pydantic schéma. Agent v textu vyhledá, roztřídí a zanalyzuje požadované informace. Díky schématu máme jistotu, že výstupem bude validní struktura dat, nikoliv textový freestyle dle agentova uvážení.
Finanční data: Následně se spouští modul pro extrakci finančních dat z Justice.cz. Ten vyhledá firmu, stáhne nejnovější dostupnou účetní závěrku, najde klíčové finanční ukazatele a vrátí je jako strukturovaná data.
Výstup: Všechna nasbíraná a ověřená data se spojí a zapíšou zpět do Excelu k příslušnému řádku.
Specifikum: Finanční data
Pojďme se na jeden z kroků podívat o něco podrobněji. Kdyby byl vývoj tohoto agenta sport, pak extrakce finančních dat by byla jeho královskou disciplínou. České firmy ve sbírce listin často zveřejňují účetní závěrky jako naskenovaná PDF (obrázky), která jsou pro běžné textové scrapery nečitelné.
Řešení jsme postavili na multimodálních modelech (Vision LLMs) bez použití tradičního OCR (optické rozpoznávání znaků). Pipeline automaticky:
Najde subjekt v rejstříku a stáhne nejnovější PDF typu "účetní závěrka".
Nejprve zkusí rychle prolétnout textovou vrstvu PDF (pokud existuje) a najít stránky obsahující klíčová slova jako "výkaz zisku a ztráty".
Díky tomu nemusíme posílat AI celou stostránkovou výroční zprávu, ale jen relevantní list.
Převede dokument na sérii obrázků.
Pošle obrázky vision modelu s instrukcí vyhledat konkrétní řádky (např. "Čistý obrat").
Tento přístup je robustnější než klasické OCR. Model vidí tabulku jako celek, ignoruje šum, razítka, podpisy i křivé skenování a vrátí strukturovaná data.
S mocí přichází zodpovědnost
Je důležité zmínit, že s automatizovaným sběrem dat se pohybujete na tenkém ledě technicky i eticky. Automatizace neznamená, že budeme bezohlední. Náš nástroj není žádný agresivní bot, který bezhlavě vysává internet.
Respektujeme robots.txt: Naše instance Firecrawlu je konfigurována tak, aby nevstupovala tam, kam si to správci webu nepřejí.
Rate limiting: Mezi požadavky jsou dostatečné prodlevy. Nechceme shodit servery státní správy, chceme jen získat data rychlostí, jakou by to dělal velmi, velmi rychlý (a neunavitelný) člověk.
OSINT principy: Pracujeme výhradně s tzv. Open-Source Intelligence daty. Tedy s informacemi, které subjekty samy zveřejnily ve veřejných rejstřících nebo na svém webu. Neobcházíme přihlašovací brány, neprolamujeme ochranu a nesbíráme neveřejné údaje.
Lessons Learned: Co jsme museli vyřešit
Vývoj nástroje nebyl jen o skládání knihoven, ale především o řešení limitů současných velkých jazykových modelů:
Pydantic jako lék na formátování: Tohle byl dlouho největší bolehlav. Model s oblibou ignoroval naše prosby o JSON, obaloval data do markdownu, přidával omáčku, přidával náhodné znaky, nebo si vymýšlel vlastní názvy klíčů. Řešením byla implementace Structured Outputs a validace přes Pydantic.
Prompt Engineering a Context Window: Museli jsme pečlivě ladit prompty. Jedno slovíčko dovedlo udělat paseku. Rovněž bylo třeba optimalizovat, kolik textu modelu posíláme. Příliš málo dat vede k neúplnosti, příliš mnoho dat mate model a prodražuje provoz.
Timeouty a Rate Limiting: Automatizace musí být ohleduplná. Implementovali jsme striktní rate-limiting a logiku pro retry, abychom nezatěžovali cílové servery.
Orchestrace nad inteligencí: Bez hard-coded kroků se AI utrhne ze řetězu. Halucinace, ztráta konzistence a nutnost spousty deterministické kontroly nás naučily, že abychom dostali konzistentní výstupy, musí být řešení víc o orchestraci než o samotné inteligenci.
Proč na tom záleží?
Možná jsem vás dosud nepřesvědčil, že stojí za to podobný nástroj programovat. Tak proč tedy?
Protože škálování. Když potřebujete analyzovat pět, deset, možná i padesát firem, uděláte to ručně. Když jich máte v seznamu sedm set, ručně to uděláte jen stěží.
Upřímně? Kdybychom počítali hodiny vývoje jen proti té jedné tabulce, dost možná by se to v čistém čase nevyplatilo. Ale není to jen o tom. My teď máme replikovatelnou pipeline, která kombinuje spolehlivost Python skriptů se schopností LLM rozumět nestrukturovanému obsahu. Když zítra přijde požadavek na analýzu dalšího segmentu trhu, nezačnou nám z té představy hrůzou vstávat vlasy na hlavě. Škálování z padesáti firem na pět set už není otázka týdnů lidské práce, ale jen spuštění skriptu a pár dolarů za API. A to nám dává svobodu věnovat se tomu, co AI (zatím) neumí.
Golden Retriever vznikl jako pragmatická reakce na nudný úkol. Ukazuje, že zapojení AI do firemních procesů nemusí znamenat revoluci a může lidem výrazně uvolnit ruce. Stejně jako u čtyřnohého společníka, i tento Retriever však potřebuje vodítko. Když mu dáte až moc prostoru a nebudete jej hlídat, dost možná se budete divit, že je vlastně docela pako.
Sdílet článek
Autor
Matěj MatoušekKavárenský analytik a datový fajnšmekr, co rád vnáší řád do informačního chaosu. Ve volném čase jezdím po světě, chodím po horách a řeším Bitcoin.
Získejte aktuální info ze světa Edhouse - novinky, setkávání, aktuální trendy softwarové i hardwarové.
Děkujeme za váš zájem o odběr našeho newsletteru! Pro dokončení registrace je potřeba potvrdit vaše přihlášení. Na zadaný e-mail jsme vám právě zaslali potvrzovací odkaz. Klikněte prosím na tento odkaz, aby bylo vaše přihlášení dokončeno. Pokud e-mail nenajdete, zkontrolujte prosím složku nevyžádané pošty (spam) nebo složku hromadné pošty.