Prezentace výsledků testování v Streamlit - 1. díl - tabulky
3.10.2022Jan Zatloukal
Streamlit je framework, pomocí kterého můžete převést data na interaktivní webové aplikace. K dispozici je zdarma a jediné, co budete potřebovat, je znalost Pythonu. Nejvíce se využívá pro zpracování vědeckých dat, ale my si ukážeme, jak pomocí Streamlit prezentovat výsledky testování.
Kromě Streamlitu si nainstalujem také Pandas pro práci s daty:
pip install streamlit
pip install pandas
Hello world
Vytvoříme nový soubor hello-world.py a vložíme do něj následující kód:
import streamlit as stst.markdown("Hello world")
Spuštěním si ověříme, že vše funguje, jak má:
streamlit run .\hello-world.py
Testovací data
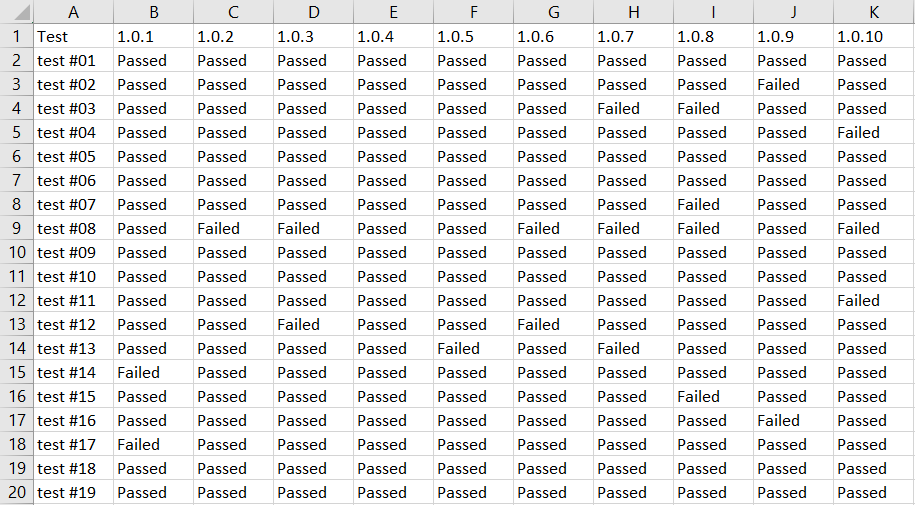
Pro účely tohoto seriálu jsem vytvořil jednoduchou tabulku s výsledky testů (test-results.csv):
Vykreslení tabulky
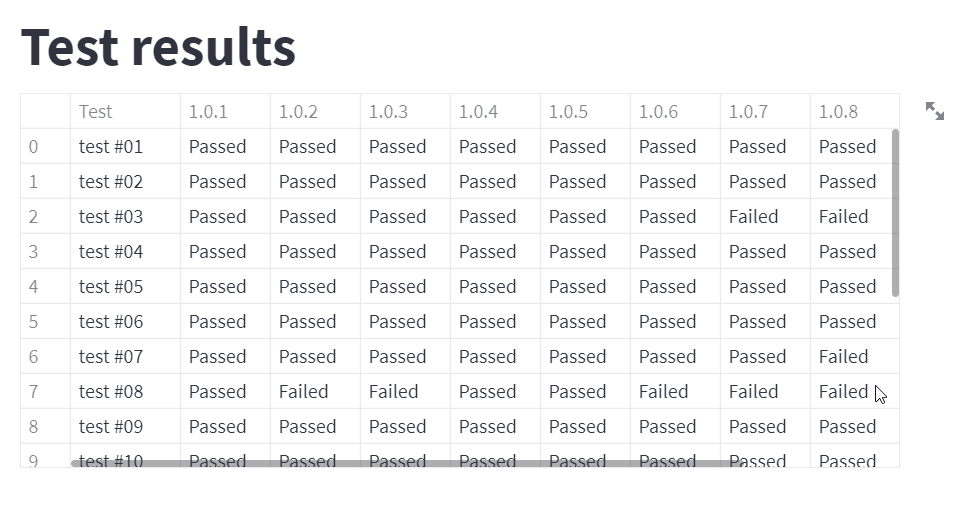
Vykreslení tabulky je jednoduché, pomocí Pandas načteme datový soubor a ten následně vykreslíme:
import pandas as pd import streamlit as st
st.title("Test results")
df = pd.read_csv("test-results.csv")
st.dataframe(df)
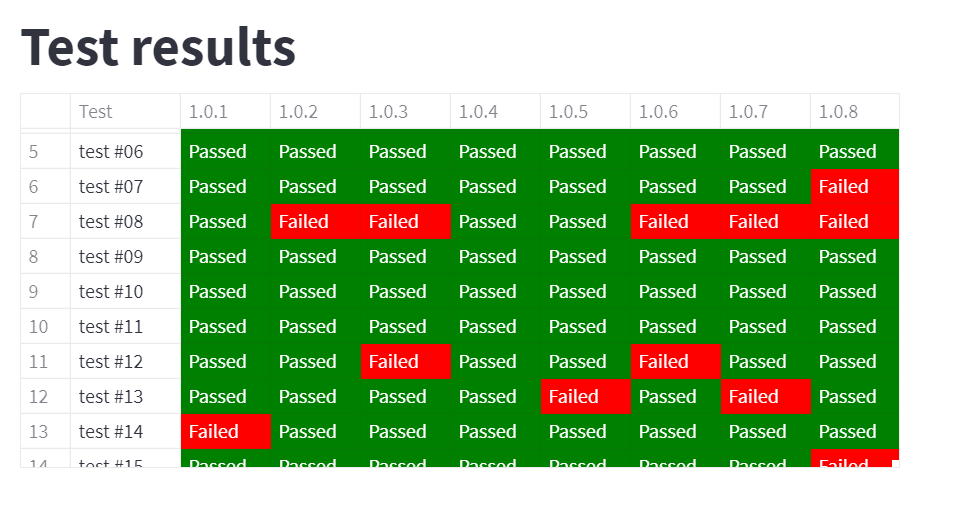
Zvýraznění pomocí barev
Následně si vytvoříme funkci colorize, ve které definujeme, jak budou buňky označené, a potom ji aplikujeme pomocí applymap. Jako subset použijeme názvy sloupců (df.columns), tzn. hlavičku tabulky:
def colorize(val):
if val == "Passed":
return f'background-color: green; color:white'
if val == "Failed":
return f'background-color: red; color:white'
else:
return None
st.dataframe(df.style.applymap(colorize, subset=df.columns))
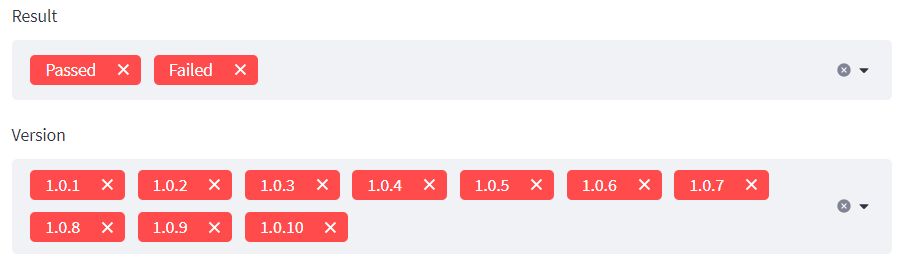
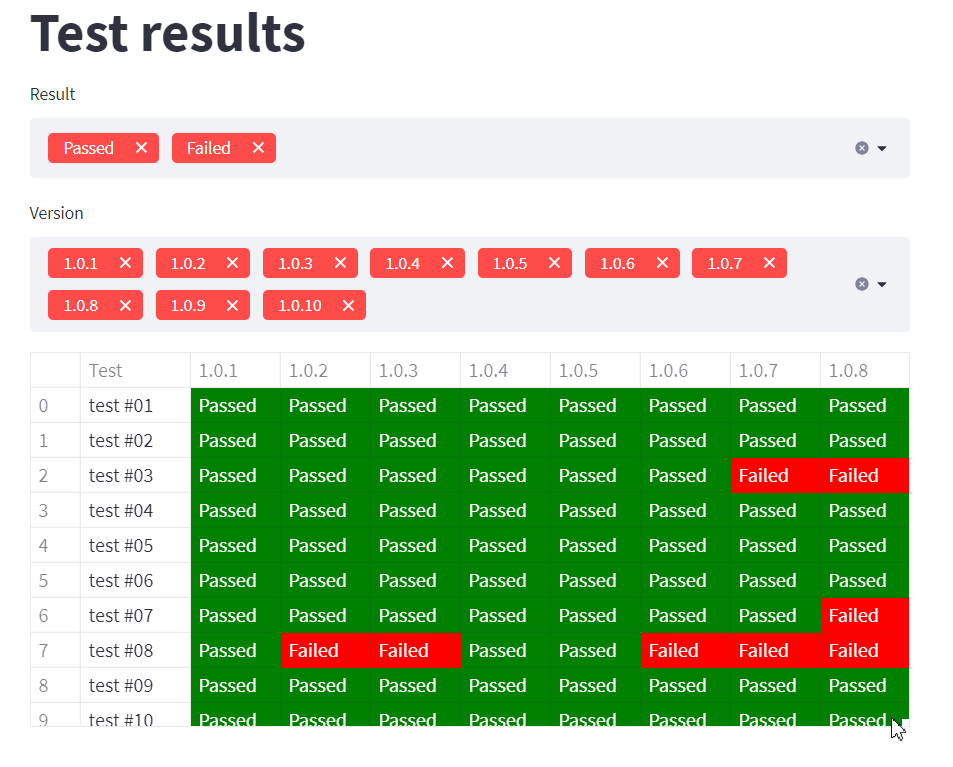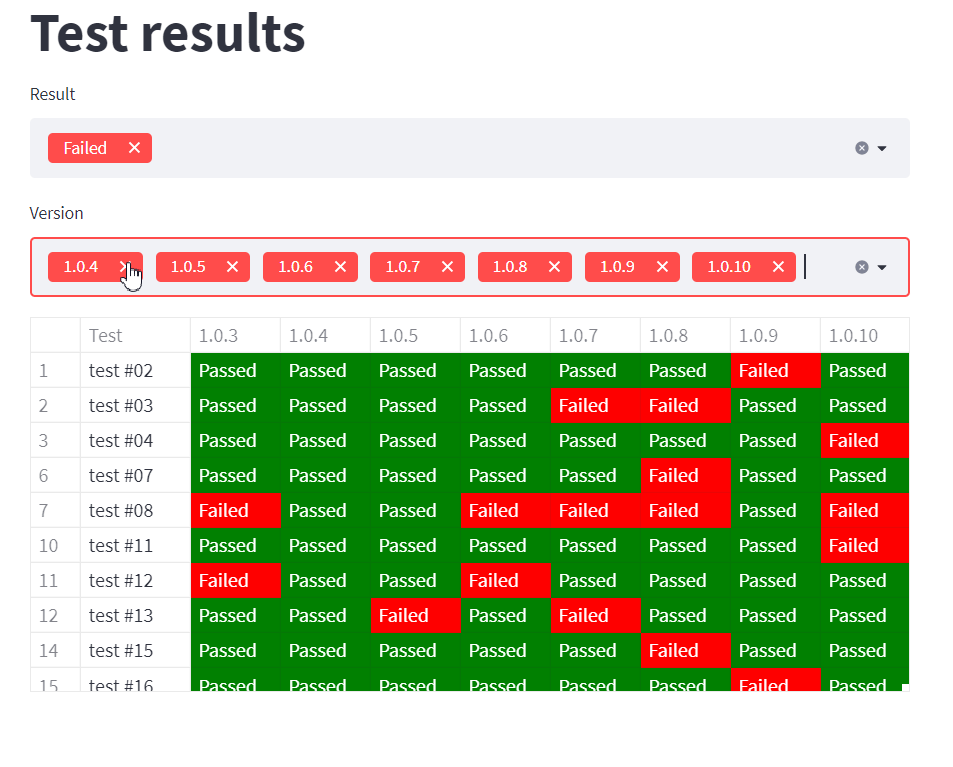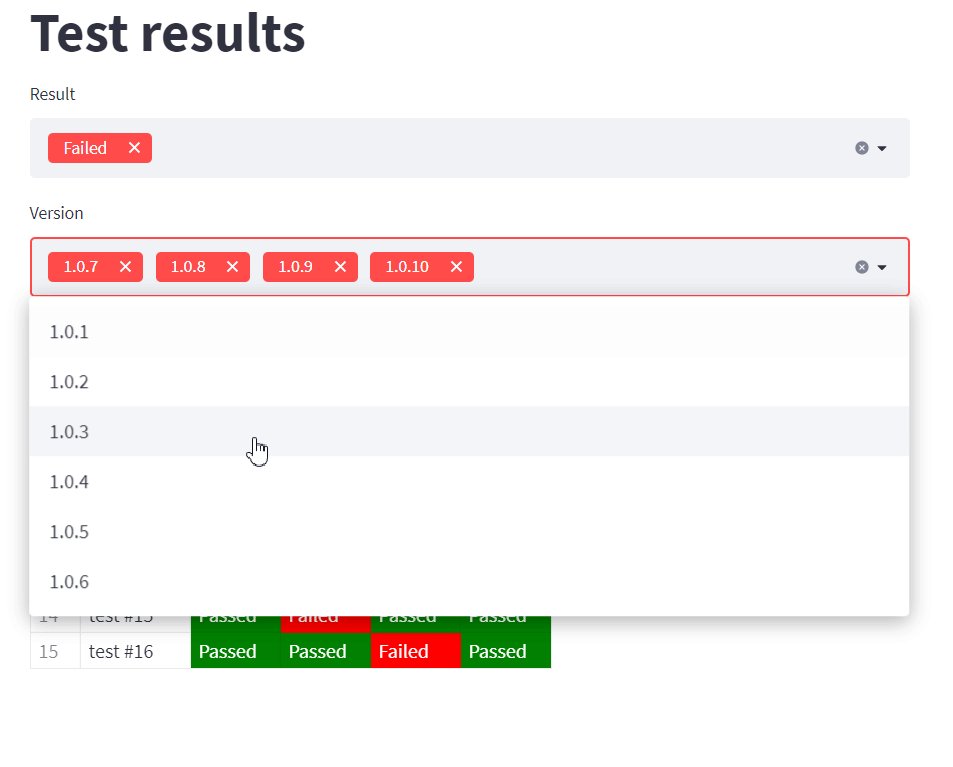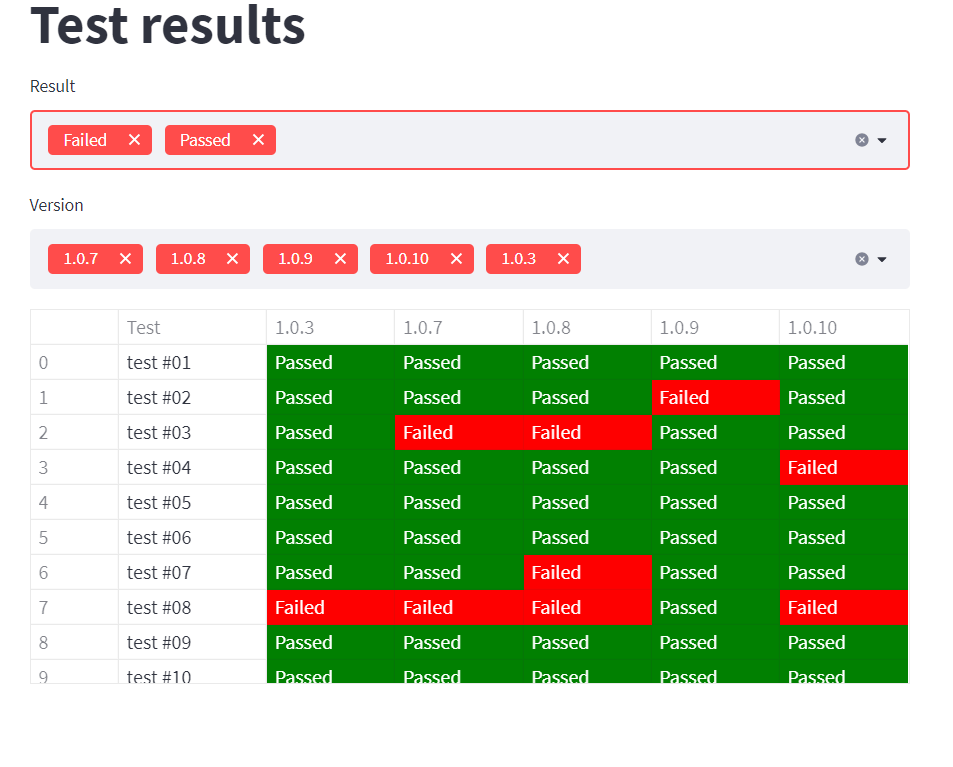
Filtrování dat
Nejdříve si vytvoříme seznam verzí, se kterým budeme dále pracovat. Pomocí df.columns zjistíme názvy sloupců, které obsahují právě číslo verze. Jen přeskočíme první sloupec, protože ten číslo verze neosahuje:
versions = []
i = 0
for version in df.columns:
if i > 0:
versions.append(version)
i += 1
A můžeme začít tabulku filtrovat. Vytvoříme si select boxy s výsledky a verzemi:
Chtěl jsem, aby ve výchozím stavu byly vybrané všechny hodnoty, proto jsem “naplnil” oba parametry options a default stejnými hodnotami.
Následně už nám stačí jen data přefiltrovat na základě vybraných hodnot. Použijeme k tomu metody pandas.DataFrame.loc a pandas.DataFrame.iloc, které nám umožňují přistupovat na jednotlivé buňky pomocí zadaných parametrů a pandas.DataFrame.isin, která nám je pomůže odfiltrovat.
Aby se nám v tabulce stále zobrazoval i první sloupec s názvem testu, explicitně ho přidáme do filtrování verzí:
Pro filtrování pomocí výsledků potřebujeme prohledávanou oblast omezit jen na sloupce s výsledky, proměnná num udává, kolik sloupců máme na filtr použit:
num = -1 * len(versions)
df = df[df.iloc[:,num:].isin(filter_result).any(axis=1)]
Jan ZatloukalTester a vývojář se zálibou v automatizaci a zlepšování procesu vývoje. Aktuálně pracuji na projektu automatizace elektronových mikroskopů v Pythonu.
Získejte aktuální info ze světa Edhouse - novinky, setkávání, aktuální trendy softwarové i hardwarové.
Děkujeme za váš zájem o odběr našeho newsletteru! Pro dokončení registrace je potřeba potvrdit vaše přihlášení. Na zadaný e-mail jsme vám právě zaslali potvrzovací odkaz. Klikněte prosím na tento odkaz, aby bylo vaše přihlášení dokončeno. Pokud e-mail nenajdete, zkontrolujte prosím složku nevyžádané pošty (spam) nebo složku hromadné pošty.