“Oh great, another generic rambling about how Large Language Models will change the world beyond recognition…” That might be exactly what crossed your mind when you saw the headline. But bear with me here. This post doesn’t promise a sci-fi revolution; its content is much more prosaic. At Edhouse, we simply needed to solve one tedious, soul-crushing task - collecting data on hundreds of companies before an upcoming trade fair. We had a choice: either sacrifice our sanity or spend time developing something that would do it for us. We chose the latter and built our own agent. His name is Golden Retriever, he eats tokens instead of kibble, and unlike us, he enjoys reading scanned financial statements.”
In the beginning, there was no grand plan to build an autonomous agent. There was just a table with 700 rows and a reluctance to spend weeks on a manual copy-paste marathon. We quickly rejected the classic route of a universal script, because writing a scraper with a set of regular expressions that would reliably pull information from hundreds of different websites would be programming suicide. There weren't many other automation options, so the question arose: “What if we unleashed this magical AI thingy on it?”
Snowball Effect: When You Realize It Actually Works
What followed was quick research into frameworks, AI-native tools, and libraries (I admit to using ChatGPT) that might make sense for our use case, a bit of inspiration from YouTube, and then VS Code, a few lines in Python, trying an OpenAI API call, assembling an agent in the LangChain framework, and giving it its first tool. The result?
"Holy crap, the outputs are actually no worse than manual analysis.”
Suddenly, it clicked. If we throw the web's chaos at the model, it finds the context itself. We don't need to write a parser for every single page. We knew we'd hit other complications, that there would be issues with hallucination, output consistency, and that one promising attempt means nothing. From that moment on however, it was clear that we would give AI a shot.
Gradually, more tools were added, and the whole thing snowballed.
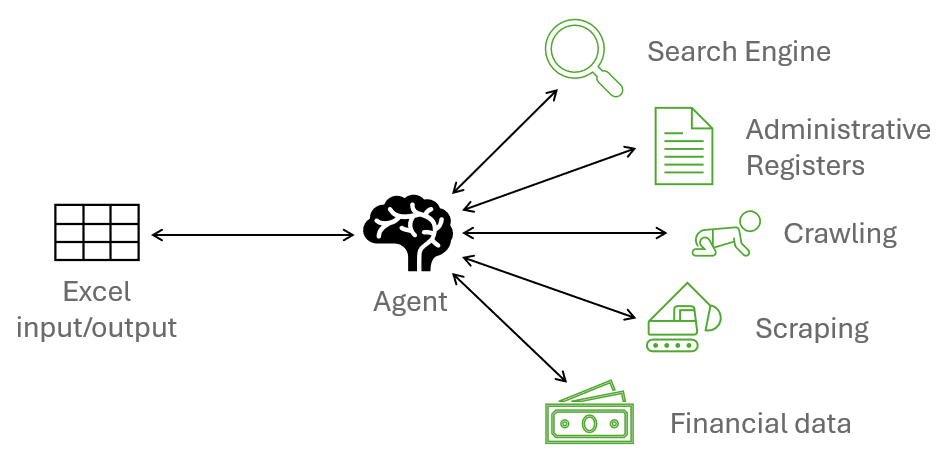
LangChain: A framework for orchestration and development of LLM-based applications. It manages the logic, memory, and sequence of steps of the entire pipeline.
Tavily: A search engine optimized for AI agents. Instead of a list of links full of ads, it returns structured context, which is used for the initial identification of a company.
Firecrawl: An open-source tool for crawling and scraping that converts web pages into clean Markdown. We run it locally in Docker to maintain control over what and how we download.
Custom Python Integration: Our own modules for communicating with registries and public records.
GR scheme
Architecture: Where Autonomy Ends and Determinism Begins
As expected, we almost immediately encountered a fundamental problem with LLMs during development: hallucination and inconsistency. If we gave the agent too much freedom over the procedure and tool selection, it often got stuck in a loop, forgot the goal, skipped important steps, and returned incomplete and, crucially, inconsistent outputs. The cognitive load was too high, and a fully autonomous agent in the sense of ReAct (Reasoning - Acting)—where the agent thinks → acts → observes → thinks again—did not make sense for our needs.
We therefore had to abandon maximum autonomy and switch to a managed pipeline. Python maintains a fixed process structure, while AI serves as the cognitive engine within individual steps and the brain that evaluates outputs from tools and decides if it's okay to proceed to the next step.
The resulting process looks like this:
GR pipeline
Input: The script reads a row from the input Excel file (company name).
Identification: The agent receives the name and uses the Tavily tool to search for the company's digital footprint, i.e., its official website and Company ID.
Validation: The found ID number is verified against the public ARES register. If the data doesn't match or the company doesn't exist, the process stops or restarts. There is no room for model creativity here.
Discovery: If the entity is valid, Firecrawl steps in. It maps the website structure (sitemap). Due to the limited context window, we don't download the whole site; the agent uses the LLM to select only relevant subpages (e.g., About Us, Careers, Products, References).
Scraping: Selected pages are downloaded and converted into clean Markdown, stripped of HTML clutter.
Extraction and Analysis: This is where the main "intelligence" kicks in. We present the model with sanitized text from the web and a strict Pydantic schema. The agent searches for, categorizes, and analyzes the requested information within the text. Thanks to the schema, we are certain the output will be a valid data structure, not a textual freestyle at the agent's discretion.
Financial Data: Subsequently, the module for extracting financial data from Justice.cz is triggered. It searches for the company, downloads the latest available financial statement, finds key financial indicators, and returns them as structured data.
Output: All collected and verified data is combined and written back into Excel on the corresponding row.
Specifics: Financial Data
Let's look at one of the steps in a bit more detail. If you think of developing this agent as cooking a delicious meal, extracting financial data would be its main ingredient. Czech companies often publish financial statements in the collection of deeds as scanned PDFs (images), which are unreadable for common text scrapers.
We built the solution on multimodal models (Vision LLMs) without using traditional OCR (Optical Character Recognition). The pipeline automatically:
Finds the entity in the register and downloads the latest PDF classified as a "financial statement."
First, it tries to quickly skim the text layer of the PDF (if it exists) to find pages containing keywords like "profit and loss statement." Thanks to this, we don't have to send the AI the entire hundred-page annual report, just the relevant sheet.
Converts the document into a series of images.
Sends the images to the vision model with instructions to find specific rows (e.g., "Net Turnover").
This approach is more robust than classic OCR. The model sees the table as a whole, ignoring noise, stamps, signatures, and crooked scanning, and returns structured data.
With Power Comes Responsibility
It is important to mention that with automated data collection, you are walking on thin ice, both technically and ethically. Automation doesn't mean being reckless. Our tool is not an aggressive bot that mindlessly sucks the internet dry.
We respect robots.txt: Our Firecrawl instance is configured not to enter where site administrators do not wish it to.
Rate limiting: There are sufficient delays between requests. We don't want to crash government servers; we just want to get data at the speed a very, very fast (and tireless) human would.
OSINT principles: We work exclusively with so-called Open-Source Intelligence data. That is, information that entities have published themselves in public registers or on their websites. We do not bypass login gates, break protections, or collect non-public data.
Lessons Learned: What We Had to Solve
Developing the tool wasn't just about assembling libraries, but primarily about dealing with the limits of current large language models:
Pydantic as a cure for formatting: This was the biggest headache for a long time. The model loved to ignore our requests for JSON, wrapping data in markdown, adding fluff, inserting random characters, or inventing its own key names. The solution was implementing Structured Outputs and validation via Pydantic.
Prompt Engineering and Context Window: We had to carefully tune the prompts. One single word could cause havoc. It was also necessary to optimize how much text we sent to the model. Too little data leads to incompleteness; too much data confuses the model and increases operating costs.
Timeouts and Rate Limiting: Automation must be considerate. We implemented strict rate-limiting and retry logic so as not to overload target servers.
Orchestration over Intelligence: Without hard-coded steps, the AI goes off the rails. Hallucinations, loss of consistency, and the need for a lot of deterministic control taught us that to get consistent outputs, the solution must be more about orchestration than intelligence itself.
Why Does it Matter?
Maybe I haven't convinced you yet that it's worth programming a tool like this. So why?
Because of scaling. When you need to analyze five, ten, maybe even fifty companies, you can do it by hand. What if next time you have seven hundred?
Honestly? If we counted development hours against just that one spreadsheet, it might not have paid off in terms of time. But it's not just about that. We now have a replicable pipeline that combines the reliability of Python scripts with the LLM's ability to understand unstructured content.
If a request comes tomorrow to analyze another market segment, the idea won't make our hair stand on end in horror. Scaling from fifty companies to five hundred is no longer a question of weeks of human labor, but just running a script and spending a few dollars on API fees. And that gives us the freedom to focus on what AI can't do (yet).
Golden Retriever was created as a pragmatic reaction to a boring task. It shows that integrating AI into company processes doesn't have to mean a revolution and can significantly free up people's hands.
Just like a four-legged companion, however, this Retriever needs a leash. If you give him too much space and don't watch him, you might be surprised to find that he's quite a bit of a dummy.
Share article
Author
Matěj MatoušekA café-born analyst and data connoisseur who enjoys bringing order to information chaos. In my free time, I travel the world, hike in the mountains, and dive into Bitcoin.
Get the latest updates from the world of Edhouse – news, events, and current software and hardware trends.
Thank you for your interest in subscribing to our newsletter! To complete your registration you need to confirm your subscription. We have just sent you a confirmation link to the email address you provided. Please click on this link to complete your registration. If you do not find the email, please check your spam or "Promotions" folder.